
Comparing Different Ways to Calculate Accuracy
Looking at the Lichess accuracy and my own accuracy functionIn recent years, game accuracy has become the most popular metric to determine how well players played in a game. It replaced centipawn loss (CPL), and is generally the better measure, as it uses the winning chances in the background, not just the raw engine evaluation.
But unlike CPL, there isn’t one clear way to calculate the accuracy of games, so I want to take a look at two different approaches to calculate the accuracy in this post.
Lichess accuracy
Let’s start by taking a closer look at the way Lichess calculates its accuracy values.
Lichess has their own explanation of how this works and since it’s open-source, you can look at the source code, if you’re interested in the actual implementation.
The first thing to understand is that Lichess uses 2 metrics derived from the engine evaluation in the background, namely the expected score (Lichess calls this win percentage, but I'll stick to expected score) and the move accuracy.
Expected score
The expected score takes an engine evaluation and returns how many points a player is expected to score from the position. So, if the evaluation is 0.00, the expected score would be 0.5, while it would be close to 1 in a winning position.
Looking at the function gives a good indication on how it works.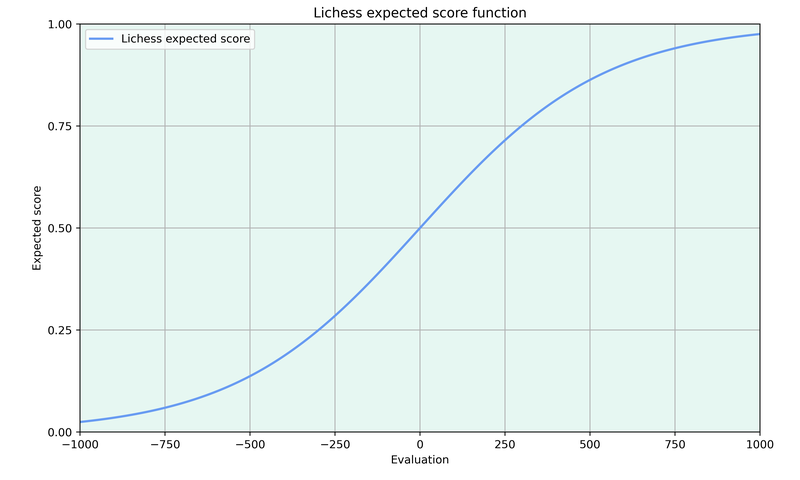
The s-shape signifies that evaluation swings in equal positions affect the outcome much more than the same centipawn swings in winning or losing positions. For example, changing the evaluation from 0 to +1 improves the winning chances for white a lot, while a change from +6 to +7 only has a small impact on the expected score.
One important detail of the expected score is that it always needs to be anchored to some specific pool of players and time control. Grandmasters will convert a +1.5 advantage in classical games much more often into wins than club players in blitz games. The Lichess accuracy is based on rapid games by players rated 2300 on Lichess.
Move accuracy
The other important metric is move accuracy.
The move accuracy assigns each move an accuracy value from 0 to 100, depending on how much the move decreased the expected score (in theory, there shouldn’t be any moves that increase the expected score, but this happens in practice due to limited engine depth, more on that later).
I couldn’t figure out how Lichess came to the exact values in their function, but the overall shape is very intuitive.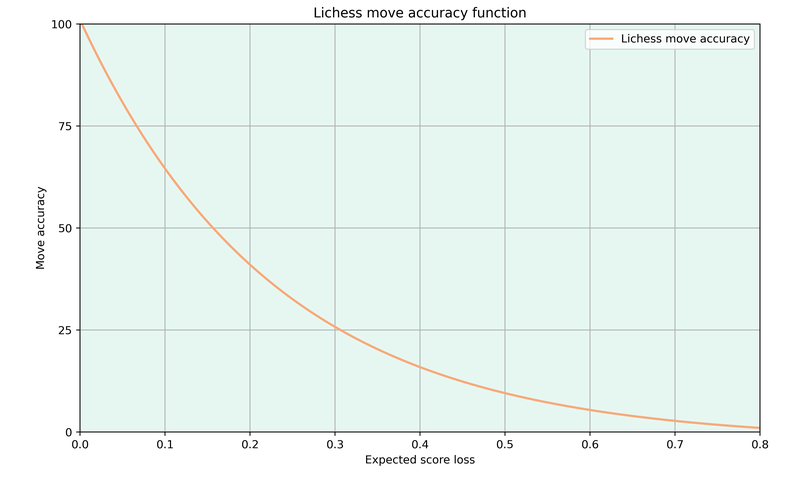
The move accuracy is once again non-linear, which means that increasing the expected score loss from 0 to 0.1 will have a bigger impact on the move accuracy than an increase from 0.3 to 0.4.
Game accuracy
Now that we have accuracies for the individual moves, we can combine them to get one accuracy value for the whole game.
The simplest way to do this would be to take the average of all move accuracies. However, Lichess does something a bit more complicated to make the accuracy closer to what players think it should be.
Using a normal average would give every move the same weight in the game. This may not be ideal, as opening moves and moves in long, drawn endings aren’t as important as moves in sharp middle games.
To assign moves different weights, Lichess divides the game into multiple smaller sections, where each section roughly contains 10 ply (so 5 moves by both sides).
This is done to calculate the volatility in each window of moves, for which they use the standard deviation of the expected scores after each move in the window. The volatility shows how much the expected score, and hence engine evaluation, moved over the course of a couple of moves. A higher volatility means that the players made more mistakes, which in turn indicates that this was an important part of the game.
These volatilities then get used as weights when calculating the weighted mean of the move accuracies. So moves that were played in a part of the game with many evaluation swings get more weight than moves in quiet parts of the game.
The final game accuracy is then the average of the volatility-weighted mean and the harmonic mean of the move accuracies.
Here is a small example with the expected scores after each move and a smaller window size of 3.
Using the volatility as weights ensures that moves played in a quiet part of the game don’t affect the game accuracy as much as moves played in a wild middle game. One side effect is that mistakes will necessarily have higher weights, as a mistake increases the volatility of the window the move is in.
The harmonic mean skews more to lower values in the data, and as we are now taking the mean of move accuracies, this means that mistakes are once again given more weight than good moves.
Accuracy based on distributions
The way Lichess calculates its game accuracy is by far not the only way it can be done.
Personally, I feel like introducing the move accuracy and putting different averages together is a bit convoluted (this doesn't mean that it isn't the best way to do it for the use case of Lichess). I’m also not sure what a specific value for the game accuracy should represent on its own.
My idea is that an accuracy of x should mean that the game is more accurate than x% of games.
To do this, one needs a baseline of games as a comparison. I’ll use classical games played between players rated 2500+. This means that games played at faster time controls or by club players will usually have a very low accuracy. But it also means that when looking at high level classical games, players will not have an accuracy of 85 or more despite losing the game.
One also needs to assign each game a value to compare the quality of the games. For this I’ll be using the average expected score loss per move, where the expected score function is again based on classical grandmaster games.
For any given game, we can calculate how much the players decreased the expected score per move on average, and with enough games, we can see how these values are distributed.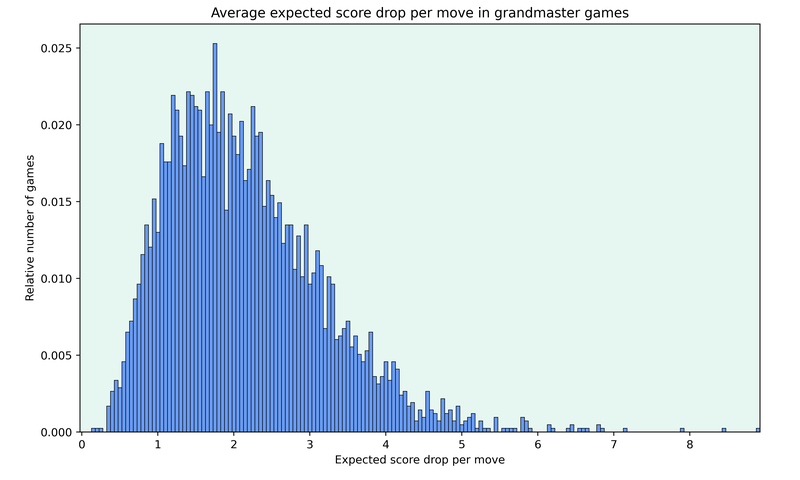
Using this data, we can now calculate which average expected score drop corresponds to which percentile of games.
Then we can calculate in which percentile the average expected score drop was for each colour in a game and then use this as the accuracy value.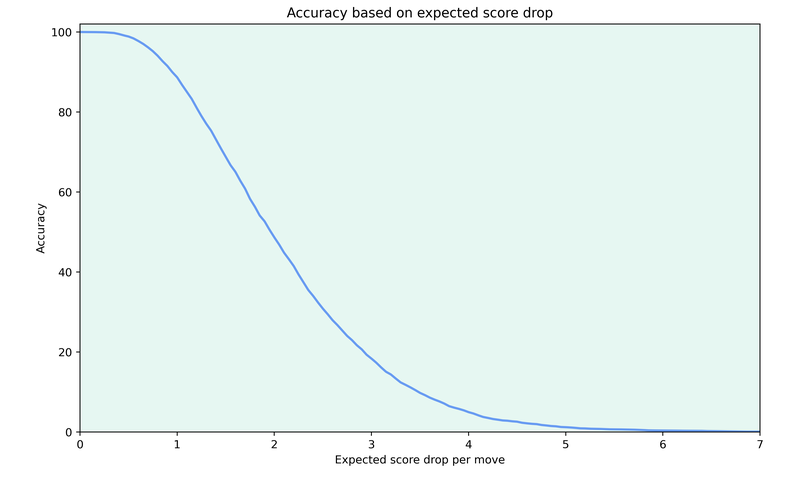
The big advantage of this approach is that the accuracy has a direct meaning, namely that an accuracy of say 80% means that the given game was more accurate than 80% of the games in the baseline dataset.
Different ways to calculate the average
After reading how the Lichess accuracy works, you may be wondering what kind of average I’m talking about, which is a good question.
Different ways to calculate the average will have different characteristics, so they will impact the accuracy value.
Let’s take a closer look at the generalised mean: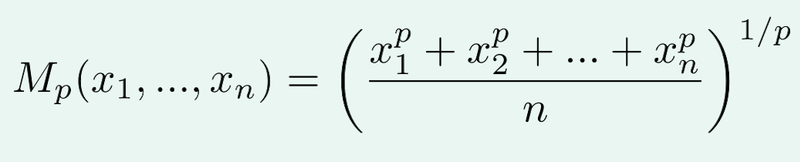
When using p=1, we are just calculating the normal average. So if we have the numbers 1, 5, 9, the mean will just be 5.
However, changing the value of p will also change the result. When p is greater than 1, the larger values in the list will have a bigger impact, which will lead to a larger mean, while the mean will get smaller when p is less than 1.
In the example above, when we use p=2, the mean will be around 5.97, while using p=0.5 yields 4.32.
Coming back to our intended use case, remember that we want to take the average of expected score losses, so mistakes will lead to higher numbers. This means that when we choose a generalised mean with p greater than 1, we will “punish” big mistakes more severely.
Taking different averages will affect both the overall distribution of the expected score losses and where each individual game sits in that distribution.
For example, here are the accuracy curves when using values of 0.8, 1 and 1.2 for p.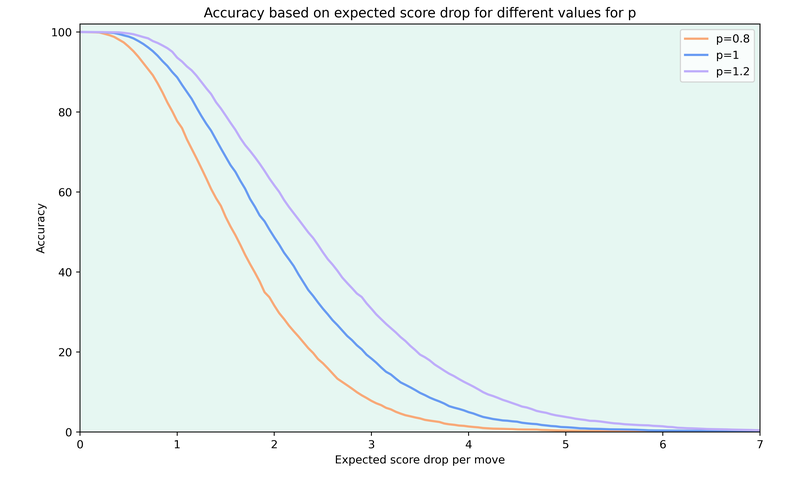
To illustrate the differences between these averages, let’s take a look at the accuracy of a couple of games. I picked the following games as they are very different from the engine’s point of view and will show the difference in the means.
- Blübaum-Sindarov, Candidates 2026: black built up a winning advantage over a couple of moves, but lost it in one move and the game was drawn after a long, equal ending
- Caruana-Wei, Candidates 2026: black missed something early on and made 2 mistakes before resigning on move 19
- Ding-Gueksh, World Championship 2024, Game 12: white slowly built up an advantage in this game and converted it without any difficulties
- Abdusattorov-Maghsoodloo, Prague 2024: this was a complicated game with mistakes from both sides, where white won in the end
Below you can also see the evaluation graphs for all these games.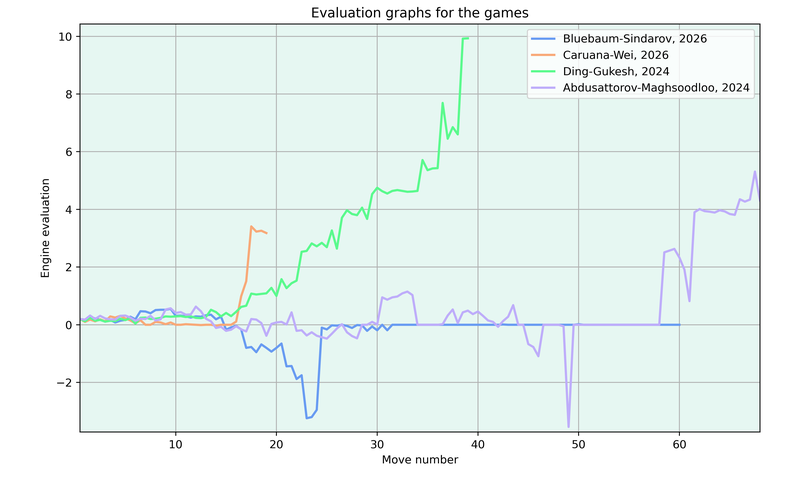
Now we can look at the different ways to calculate the accuracy for these games.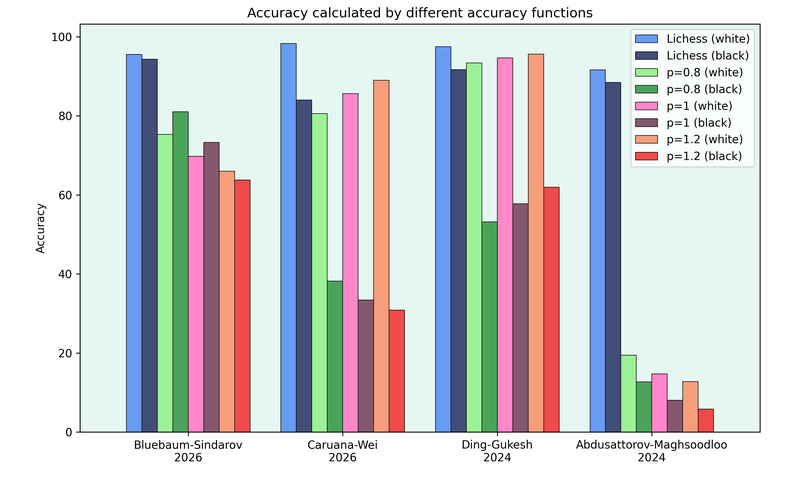
The first difference is that the Lichess accuracy is always higher, which is to be expected. It’s also clear that the accuracy based on the GM games is much more sensitive. There are big differences between white and black in the 2 decisive wins, while the accuracy for the Abdusattorv-Maghsoodloo game is below 20, which you’d never see on one of the online sites. But it makes sense to use the full range from 0 to 100.
The Caruana-Wei and Ding-Gukesh games nicely illustrate the difference between the different values for p in the generalised mean. In Wei’s loss, he made two big mistakes, which contribute more for higher p-values, so his accuracy goes down as p increases. On the other hand, Gukesh made multiple inaccuracies, but no bigger mistakes, so the accuracy gets better as p increases.
The Blübaum-Sindarov game is also interesting. For p=0.8 and p=1, the accuracy of black is slightly higher than white’s, but this flips for p=1.2, which is also in line with the Lichess accuracy. This is because Sindarov built up his advantage over multiple moves but lost it with a single mistake, which gets “punished” more severely by a higher value of p.
One thing I also want to point out is how much the accuracy changes when players play out a long ending.
When I remove all moves starting from move 33 in Blübaum-Sindarov, the Lichess accuracy changes from 95.5 to 92.8 for white, and from 94.3 to 90.6 for black. The p=1 accuracy changed from 69.7 to 21.7 and from 73.2 to 26.7, for white and black respectively. This is a massive change and illustrates how volatile the grandmaster based accuracy can be.
I don’t really know how to deal with such situations. There are obviously many clearly drawn endings being played out, but at the same time there are many complicated positions which get evaluated as 0.00. So if players play out an equal position without making any mistakes, it’s difficult to say how much this should contribute to their accuracies.
Ideally, one would calculate an accuracy value that weighs the individual moves based on the complexity of the position. I’ve written about the sharpness of a position in the past, and I’ll hopefully revisit that topic soon, so I’ll keep that idea in mind.
About engine evaluations
Finally, I also want to mention that engine evaluations are the basis of all accuracy values, but they are by far not perfect.
The big problem is that the evaluation can fluctuate from move to move, as playing out a move basically increases the engine depth. This means that a player could play the best move and the evaluation decreases, or a player could play a move that moves the evaluation more in their favour, which, in theory, shouldn’t be possible.
The only way to tackle this issue would be to increase the search depth on each move. However, this isn’t very practical when analysing a lot of games, and in openings and early middle games, it would probably take hours to get to a stable evaluation in a single position.
Final thoughts
Personally, I like the accuracy calculated with p=1, as it should mean that in case of a draw, both players have the same accuracy, at least when there aren’t any jumps due to the limited engine depth.
But I also get the idea of trying to weigh the individual moves based on how difficult a position is to play. Let me know what you think about these different accuracy values and if there is one that you prefer.
If you've enjoyed this post, check out my Substack.
You may also like
 jk_182
jk_182How Opening Advantages Translate into Results in Online Games
Measuring conversion rates in online blitz and bullet games for 1200 to 2400 rated players jk_182
jk_182How the Evaluation and Clock impact Results of Blitz Games
Looking at Lichess games to find the effect of the remaining time and evaluation jk_182
jk_182How have White's Responses to the Najdorf Changed over the Years?
Looking at popularity of white's 6th moves in the Najdorf variation jk_182
jk_182Do Attacking Players play more Forcing Moves?
Finding forcing moves and looking through the games of world champions jk_182
jk_182Predicting the Winner of Tournaments
Using game predictions to predict the outcome of a tournament Bosburp
Bosburp