
Padmanaba01, CC BY-SA 2.0
'F' is for Forget-about-it (?)
Looking at pawn move accuracy with the help of lots of dataIntroduction and methodology
In his videos, IM John Bartholomew calls the f-pawn the 'forget-about-it' pawn, meaning that you should be careful when you decide to push this particular pawn forward. This got me thinking -- pawn moves are rather special in a game of chess as they are due to their nature irreversible. But they are also very simplistic since---capture notwithstanding---you always just push a pawn one or two spaces ahead. This means that pawn moves are basically the same across a myriad of games and positions...and one should be able to look at them statistically.
In order to do just that, I downloaded the April 2023 games from the Lichess database and wrote some Python code to process them. In a nutshell, the first Python script:
- Scans through the downloaded games, discards the non-evaluated ones,
- Goes through a selected number of evaluated games (1,000,000 in this particular example),
- For each game it goes through, it looks at each pawn move excluding captures. It then calculates the accuracy of the given move and stores the accuracy in a dictionary.
- The resulting dictionary is stored in a JSON file.
The second Python script then reads the dictionary and visualises the average accuracy values of each move on a chessboard.
The code is not very complex and the analysis is not very thorough: one could for example filter the game processing by player rating or positional data (such as castled: yes/no), so I encourage the readers to play with the code a bit! But for now, let's have a look at some results.
Results
Note that the results shown below have been obtained from 1,000,000 evaluated Lichess games, indepently of player ranking and/or game time control.
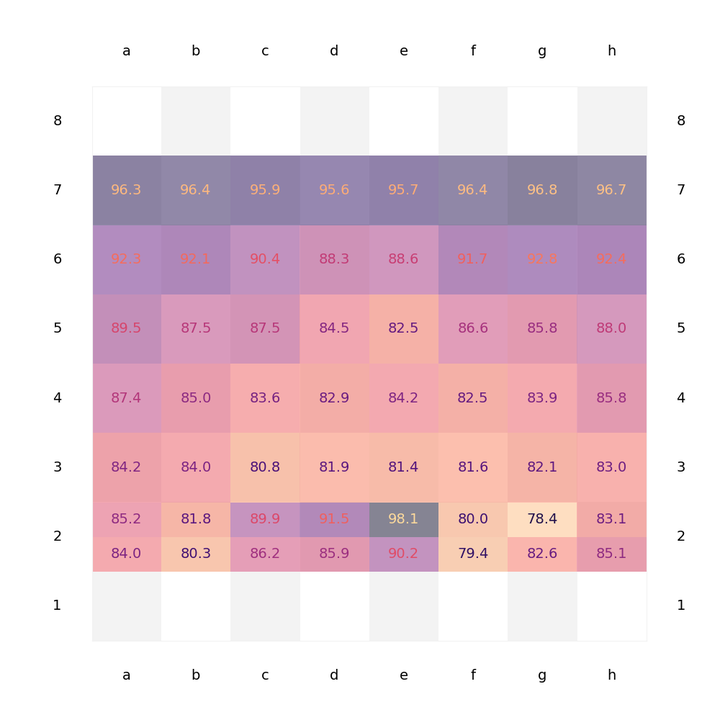
Figure 1: Average accuracy of white pawn moves in % written for starting squares, i.e. accuracy for e.g. 'd3-d4' is indicated on square d3. For second rank moves, the higher number indicates the move by two squares (e.g. e2-e4) and the lower one the move by one square (e2-e3).
In Figure 1, accuracy for white pawn moves is shown. We can notice the following:
- All c-,d- and e-pawn moves from the starting position are highly accurate. This is most probably due to the book evaluation in the opening. Conversely, b-, f- and g-pawn moves are marked as quite inaccurate.
- Pawn move accuracy increases for each file as we move to higher and higher ranks with the 7th-rank moves being almost perfectly accurate.
- Wing-pawn moves (a- and h-) show significantly higher accuracy than the centre ones. It seems thus that judgment calls regarding these moves are easier than for the central-pawn ones. Indeed, pawn moves in the wider centre rank among the lowest-accurate ones.
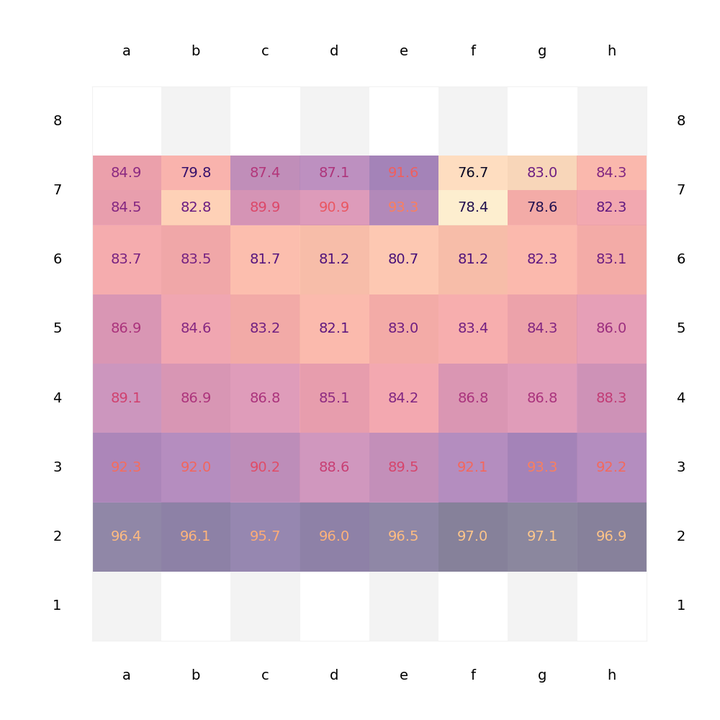
Figure 2: Average accuracy of black pawn moves in % written for starting squares, i.e. accuracy for e.g. 'd6-d5' is indicated on square d6. For seventh rank moves, the lower number indicates the move by two squares (e.g. e7-e5) and the higher one the move by one square (e7-e6).
A brief look on a similar analysis for black moves indicates that the pattern is rather symmetric, see Figure 2.
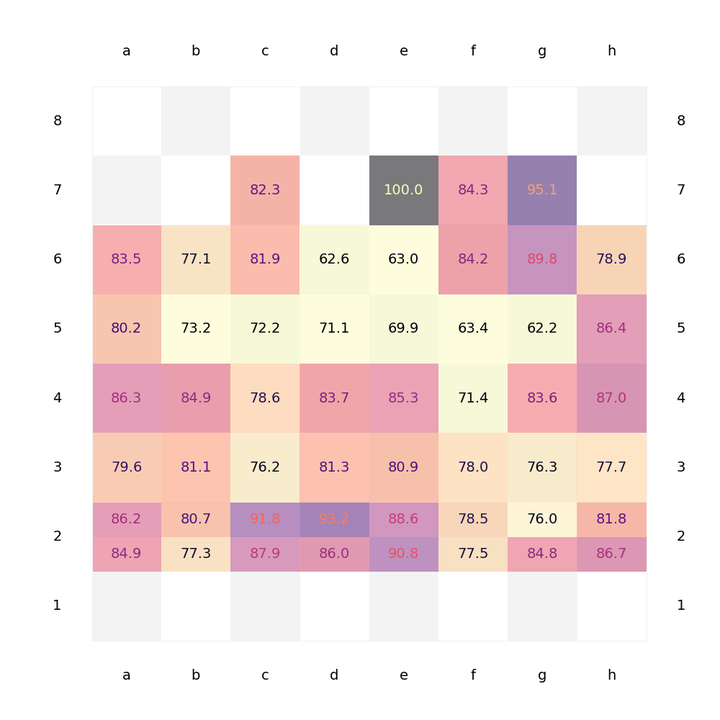
Figure 3: Average accuracy of white pawn moves in % written for starting squares, i.e. accuracy for e.g. 'd3-d4' is indicated on square d3. For second rank moves, the higher number indicates the move by two squares (e.g. e2-e4) and the lower one the move by one square (e2-e3). Only moves 2-10 are considered.
Before I close this blog post, let's have a look at a subset of the data, including only moves 2-10 for the white player. This way, the book evaluation for the first move is excluded and we can focus on the opening and early middlegame. This data as shown in Figure 3 is of course more noisy due to the reduced statistics, especially for moves such as those from the seventh rank (hardly achievable within the first 10 moves of the game), but, interestingly, now a different pattern emerges in the centre of the board. The d- and e-pawn moves up to d4-d5 and e4-e5 score rather high accuracy, while essentially all moves starting on the fifth rank (except for wing-pawn moves) end up being highly inaccurate. And it can be seen that, in this limited subset of moves, the f-pawn moves score the lowest overall: one could say that, indeed, the f-pawn is the forget-about-it pawn.
Of course, in the discussion above, I have only touched on the information contained in the data. What do you think? Are there any interesting patterns you can spot? And does it even make sense to use such statistical and synthetised data to inform your chess play?
Let me know!
Title image: New York City by Padmanaba01, licensed under the CC BY-SA 2.0 license.
You may also like
 GM Avetik_ChessMood
GM Avetik_ChessMoodSLP Method - How to save lost chess positions?
Save losing positions in chess, trick your opponent and become a tough-to-beat player by following t… NM Chess-Network
NM Chess-NetworkMagnus Carlsen is a Dragonslayer
An accelerated edition FM CheckRaiseMate
FM CheckRaiseMateCreativity in Training
Ideas from two very different adult improvers GM NoelStuder
GM NoelStuderThe Magic Of Self-Confidence
Some time ago I asked a young compatriot what goals he set for his career. A 17-year-old FM told me … GM NoelStuder
GM NoelStuder